There are few data science project management methodologies such as:
But before moving towards the details, let us have a look what actually is data science.
Data Science is the study of information gathered from large amount of complex dataset. It involves different concepts of statistics and computations to drive useful data for decision making purposes.
Data Science is not a new field of study, rather it was introduced 3 decades ago. The term “data science” was used for “computer science” previously, but since early 2000s it was considered as an independent course. Now, Let us dig deeper into the detail of the concepts and terminologies used in data science.
There are 4 stages or levels of analytics that are considered to be the best for decision making process.
It is essential to understand the 4 stages of analytics in detail.
Descriptive analytics is the first level of analytics and it is considered the most time consuming task. This is the most important step of decision making because all the other concepts are based on it. In descriptive analytics, raw data is collected and filtered to reuse it for useful purpose. This useful information is used to draw conclusions and important decisions. This step is also considered as the observation step and we move forward into insights, which is the 2nd step.
As the word “diagnostic” suggest, we move forward to check why the graph is sloping that way. Unlike, descriptive analytics where we just focus on what is happening but in diagnostic we will focus on why it is happening this way. We diagnose the data and drive the conclusions over it. Let us have a look at the example.
Suppose you visit the doctor and the doctor says you that you are sick, not more than this. It means that he has observed you and drive the conclusion that you are sick but he has not diagnosed you and tell you the problem that why you are sick. You have sore throat or you have typhoid? No one knows. Same is the case with analytics, at first you analyze the data and then diagnose it.
Click here to know more about Data Science Course in Hyderabad
In predictive analytics, organizations predict the outcome of the first two analytics. They predict different parameters of success and test them to check the reliability of their decision. It involves different machine learning concepts, AI, data science, and statistics to analyze the data and make predictions for the future.
By the combination of these 3 stages of analytics and different ML and AI concepts, organizations can make the decision about the failure or success in the future. Predictive analytics helps the organizations to make better decisions and look forward upon the behavior of the data. Unfortunately, many organizations ignore this stage and focus only on first two stages. Predictive analytics is applied in many applications such as health care, customer relationship management, risk management, fraud detection, theft detection, under writing and direct marketing etc. Processes of predictive analysis are:
It is the most powerful and most advanced phase of analytics in which data itself prescribe the future of the organization. It automates the ability of data to make decisions and prescribe what should be done next. At first level you just observe the behavior of the data. In the next level you diagnose the data and answer that why the data is behaving that way, and then we make predictions that what will happen.
In the last and most vital step, the data will guide us that what should you do for the future benefit. This is the reason why prescriptive analytics is so important. For the success of the organization it is important for all four stages to work together. If any one of the phase is not working well, the decision making strategy will be failed.
Machine Learning is the application of Artificial Intelligence, in which computer systems automatically learn and improve their ability to learn from past experiences. Computer programs are developed in such a way that they access the data for example images, learn from that images and process further. There are several different categories of learning in machine learning but we will discuss here:
Supervised learning is all about labeled data. As it is clear form the name that a supervisor or a teacher who tells you the correct answer. Supervised learning means that the machines are trained using the labels. Label is a tag which is placed on an object, for example we give the image of dog labeled as dog. In this way we have guided our system that this is the image of a dog.
Afterwards, you train your machine by feeding thousands of images of a dog. When you will give an image that has a dog and an elephant, your machine will classify the dog through its features.
Supervised learning is further divided into two categories of algorithms:
Unsupervised learning means that you train the machine using the data that is anonymous to the machine. You give the dataset to the machine that is neither labeled nor classified and you ask the algorithm to classify the images without any training. Machine divides the objects on the basis of size, color, and pattern. This is basically known as clustering, which is very popular algorithm of unsupervised learning.
For example, you feed the image having both dog and a man. As there is no label or tag on the image as machine has no idea that whether it is a dog, a cat or a man. But machine will distinguish them on the basis of similarities and differences.
Reinforcement Learning is the part of machine learning in which the machine learning or deep learning models are trained to make complex decisions. The software agents try to achieve a goal or take action in difficult and complex situations. Unlike supervised learning, where labels guide the machine about the object in the image or in simple words the model is trained by the correct answer. In reinforcement learning the agent learn from its experience and make the decision on the run time. In reinforcement learning, the output depends upon the input and the next input depends upon the previous output.
Reinforcement Learning is of two types:
It is the type of reinforcement learning in which a particular action makes a positive change in behavior.
It is the type of reinforcement learning in which the behavior starts increasing because the negative effect is stopped or neglected.
In data science, data is the king and if we lack data or there is no data we cannot do anything. There are several questions arise when we start working over data. These questions are:
All these questions are answered by data science project life cycle. We will discuss each step of project life cycle in detail. We will choose the OSEMN framework, which will cover the complete process from data gathering to interpretation.
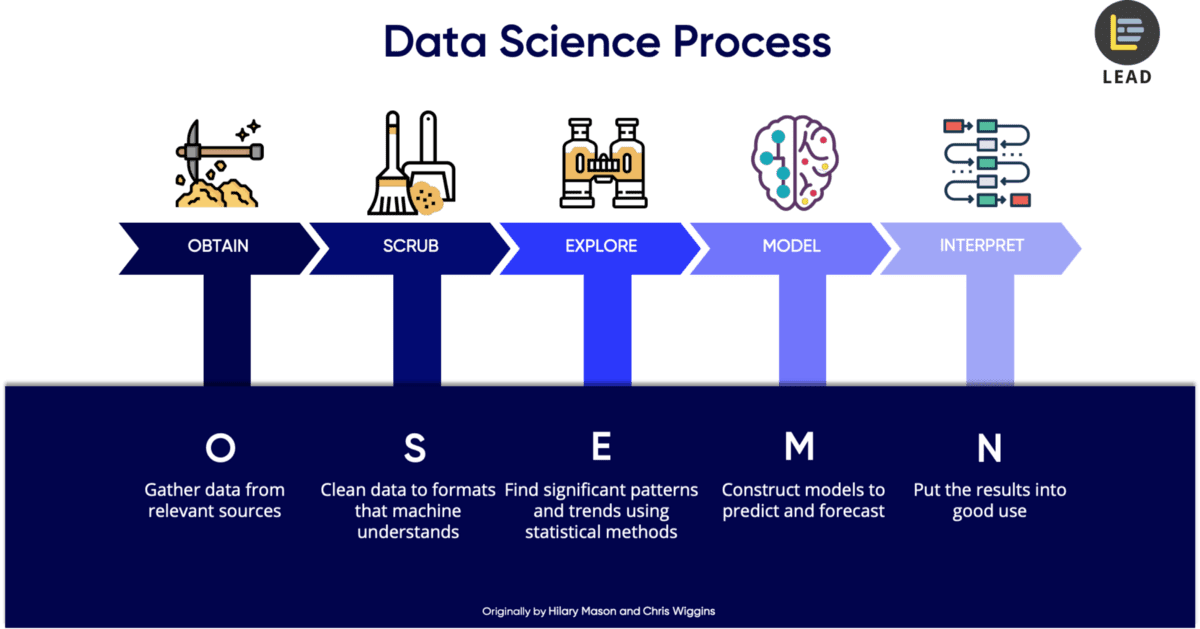 data-science-project
data-science-project
There are following steps in this framework:
This is the first step in data science project life cycle. It is the most basic step where we gather the required data from the available data sources. In order to retrieve the data you need to apply different queries to the database. The diverse kind of databases you may experience resemble PostgreSQL, Oracle, or even non-social databases (NoSQL) like MongoDB. Another approach to get data is to scratch from the sites utilizing web scratching apparatuses, for example, Beautiful Soup. Moreover, another well-known choice to assemble data is interfacing with Web APIs. Sites, for example, Facebook and Twitter permits clients to associate with their web workers and access their data. You should simply to utilize their Web API to slither their data.
We can also gather the data from different scripts and records for example, downloading it from Kaggle or existing corporate data which are put away in CSV file (Comma Separated Value) or TSV (Tab Separated Values) design. These records are level content documents. You should utilize exceptional Parser design, as a customary programming language like Python doesn't locally get it.
After obtaining the data, the next step is to filter or scrub the data. Scrubbing the data is very important because we need only important data that is useful for us. We have to garbage the extra data otherwise it will be useless for us. There are a lot of things you need to do in scrubbing your data. If your data is in a special file format such as CSV file, then you need to organize those file and make a single repository so that it will be easy for you to analyze it. You can also add missing information where needed and replace the values accordingly. In short, you have to merge the data, neglect the ambiguous data, and delete the data which is useless for you.
After gathering the data from all resources and scrubbing it, you need to examine your data before applying Machine Learning and Artificial Intelligence techniques to it. There are several types of data such as ordinal data, descriptive data, categorical data, numerical data, and nominal data.
Moreover, you need to extract different features form your filtered data. The features can be anything related to your data. In ML and AI, the features can be edges, corners, and slope etc. we will visualize the data using data visualization tools like Tableau.
Before rushing to the data modeling step, you need to ensure that your data gathering, filtering and extracting the useful information through it is done very crucially. When you are confident about the first three steps than you are good to proceed towards the modeling step.
In data modeling, the main task is to reduce the dimensionality of your filtered dataset. All the features and properties of the dataset is not required to predict the model rather you need to select the important features and predict on the basis of that.
Interpreting the data is the most powerful step in data science project life cycle. In this step, your technical skills are not enough to interpret the data but you also need a non-technical or layman to describe your findings. If the presented data is understood by the non-technical audience than you are successful, otherwise your communication is not effective and you need to work on that.
Machine Learning frameworks are the tools or libraries that are used by the developers to develop machine learning and deep learning models. As you all know what is machine learning let us directly dive into the popular tools that can convert your simple AI project into the wonderful innovation. According to Ml and AI experts, following are the best frameworks for building machine learning systems.

TensorFlow is an open source framework which was released in 2015. It was developed by Google Brain team using Python, C++ and CUDA and is considered the best framework to develop ML models. This tool is used for data flow and training Machine Learning models very easily. It is also used for high mathematical computations and applications such as neural networks and deep neural networks. It also comes up with TensorFlow Lite to train Machine Learning models on your smart phone.
It is a vast ML framework which can be computed on CPU as well as GPU. It also supports classification, regression and association along with other deep neural networks.

Google cloud ML engine is one of the best framework for data scientists and deep learning enthusiasts to develop machine learning models. It gives data scientists, an opportunity to build models that can help in prediction and training services. It is also used in weather forecasting systems to measure the density of clouds. Moreover, these forecasting services can be used independently or solely.

Apache Mahout is an open source framework developed by Apache software foundation. It is the deep learning framework build on the top of Apache Hadoop that operates on a distributed linear algebra library to implement machine learning algorithms. It is very extensive and easy to use framework that is used for clustering, regression and batch-based collaborative filtering.

Gunnar Raetsch and Soeren Sonnenburg developed Shogun in 1999 that supports vector systems that support classification and regression systems along with other machine learning systems. Shogun is an open source machine learning framework used in designing data structures and algorithms. It supports C++, R, python, java, octave, ruby, C#, MatLab, Lua programing languages. It is used to develop hidden Markov models and can process extensive datasets. This is the main reason why shogun is extensively used in ML modeling.

Sci-Kit Learn is developed by David Cournapeau and is compatible with windows, Linux and MacOS. It is also an open source machine learning framework for the python programming language. It supports several classification, regression and vector systems. It is also very easy to learn by beginners because its documentation is widely available. It is also used in data mining and data analytics.

Python was released back in 2016, developed by Facebook’s AI Research Lab (FAIR). It is written in Python, C++ and CUDA language. Since the release, several researchers are adopting PyTorch because of its high computational power. It can build highly complex neural networks. It is developed to run high numerical computations which becomes easier as it is developed in Python programming language. PyTorch is the best framework for developing hybrid front end and computational graphs. It makes it easy to operate as compared to others.

H2O is an open source deep learning framework mainly used in data science in analytics. It is used to predict the decisions in prediction analytics. It helps in making decisions on the basis of data available. This framework is use for risk analysis, fraud detection, insurance analytics, whether forecasting systems, health care systems, advertising and predictive modeling systems.

Microsoft Cognitive Toolkit, previously known as CNTK is an open source deep learning library. This deep learning framework was written in C++ and productions readers developed by Microsoft Research Team. Microsoft cognitive Toolkit is used to drive neural networks in the form of graph and it was used by Microsoft for its products such as Skype, Bing, Cortana and Xbox. It is used in various ML models such as convolutional neural networks (CNN), recurrent neural networks (RNN) and deep neural networks (DNN).

Apache MXNet is an open source deep learning library which is used to train and deploy Convolutional Neural Networks and Deep neural Networks. It was developed by Apache Software foundation and it can be used with multiple programming languages such as C++, Python, R, Julia, Java, JavaScript, Go, Perl and Scala. Apache MXNet can perform be executed on both CPU and GPU.

Apple’s core ML is used to develop machine learning models that allows image classification, regression, NLP, sentence classification and object detection and recognition. It can be used with CPU and GPU for better performance. This ML library is easy to use and beginner and intermediaries can also learn it easily.
There are various processes of data mining that are used in data science projects. Some of them are listed below:
Before moving towards the detail of each methodology, let us have a brief introduction to data mining.
Data mining is the art of finding hidden relationships among the data in large datasets. Data mining uses the techniques of Machine learning, statistics, Artificial intelligence and some database management techniques. The models trained using data mining techniques can be used in fraud detection, theft detection and marketing strategies. There are several types of data on which data engineers can perform data mining. Following are the types of data:
KDD is a methodology in data science in which data engineers extract the required information from the raw data to make it useful for their purpose. It has 5 steps:
We will discuss all in detail.

In this step, data engineer selects the larger dataset from where he needs to extract the useful information for further use.
Data is filtered or scrub as the original data has many unnecessary details in it.
Using transformation methods, data is reduced dimensionally. You need to extract special features for example eyes, nose, ears, edges and corners. You cannot apply ML or AI algorithms before dimensionality reduction.
It is the practice of examining larger datasets in order to obtain the information of your interest. For example prediction and prescription.
After mining, engineers evaluate the results against the mined data patterns.
SEMMA is the abbreviation for sample, explore, modify, model and assess. It is another data mining approach which is somehow similar to KDD but it can be applied on simple data science projects. Unlike KDD, SEMMA is a cyclic in nature and it strictly follows it.

There are 5 steps involved in SEMMA.
A sample is the part of information that is extracted from the larger dataset and it can be manipulated very easily.
Engineers explore the data and find useful trends and anomalies by understanding the dataset.
This step is similar as transformation in which unnecessary data variables and outliers are ignored. Engineers create and select the data for further processing.
In this step, different modeling techniques are used. The techniques are selected on the basis of nature of goal that you want to achieve through data mining.
It is the final stage and at this stage results are evaluated and check whether the finding are reliable or not. Data scientists measure the performance and if the goal is not reached, all the steps are repeated.
CRISP – DM is an abbreviation that stands for cross-industry standard process for data mining. This process model is used in almost all types of data mining projects including simple and complex one. This process model is also same as KDD and SEMMA in its cyclic nature but it is only different in the way that we can traverse back after moving forward as well. For example if you are at modeling step and you realize that the data is not enough to process further then you can move back to the data preparation step without repeating the whole cycle again. This model has 6 steps that describes the data science project life cycle.

This process model was established in the late 90s and since then it has become the most advantageous and reliable process model in the data mining and data science projects. This process model is very suitable with the agile methodology and it stream lines the processes.
According to our point of view, KDD, CRISP – DM and SEMMA are almost same with minor differences. KDD and SEMMA are almost same, just the difference is that KDD does not follows cyclic nature but SEMMA strictly follows it. SEMMA can be used in simple data science projects rather than data specific ones. On the other hand, KDD specifically focuses on data specific projects where it has to deal with large and huge datasets and it process all the steps of it. CRISP – DM differs in the way that it combines the Sample and explore process of SEMMA and selection and preprocessing of KDD and makes it business understanding. One of the major difference is that CRISP – DM offers the deployment process also, which is not present in KDD and SEMMA.
Now we will discuss each step in detail. Let us start from the initial stage that is business understanding.
This is the first and important step of project life cycle. This phase is related to information gathering and requirement elicitation. Moreover, other than data science or data mining projects, success of every other project strongly depends upon how well the requirements are elicited from the project stakeholders. This step is the base of other steps and procedures that is why we are supposed to correctly determine the business goals and constraints of the project. This step is further divided into few stages.
In this step, you sit with the project stakeholders and ask them to give you all the details related to the project. What is the business problem what is he expecting to achieve? You elicit each and every requirement from your stakeholders. You note the constraints applied on the project by the customer. You also need to focus that the goals and objectives of the customer should be “SMART”.
“S” = specific
“M” = measurable
“A” = attainable
“R” = relevant
“T” = time bound
It means that the customer should not demand the product which is neither reliable nor possible for someone to develop. It should be time bound, it often happens that client demands the complex project in very limited time.
In this step, data engineer check for the resources available to accomplish the project. He analyze the project requirements, business constraints and assumptions. He note down the possible risks and contingencies. Moreover, a cost benefit analysis is carried out to determine that how we will invest and get revenue in future. Let me briefly explain what is cost-benefit analysis?
Cost Benefit Analysis is one of the techniques used in feasibility study phase of the software project management. In this technique, we evaluate the cost versus benefits in project proposal. There is a list of expenses of every project and the expected benefits after successfully completing the project. Here you can calculate return on investment (ROI), internal rate of return (IRR), net present value (NPV) and the payback period.
The purpose of cost benefit analysis in the project management is to analyze the pros and cons of various key points including transaction, different tasks, software requirements and investments. In short, Cost Benefit Analysis gives you the best approach to achieve your goals in least possible investment.
This is the third step in business understanding phase of CRISP – DM. In this phase, along with defining business success criteria and objectives, you should also define the data mining goals. What is the criteria of their success? Means that in what ways they will be assure that the success is achieved. State the conditions that how the success looks like from the data mining experts perspective.
After gathering all the possible business requirements and functional requirements along with the constraints, you are now good to proceed to the project plan development phase. In this phase, you develop the project plan by defining all the steps involved in the completion of project. You will describe about the tools and technologies which will be used in the complete project.
The next stage in CRISP – DM is data understanding. Let us have a look on that.
This is the second phase of CRISP – DM and it runs on behave of first step that is business understanding. In this step, engineers focus on identifying the datasets, collect the relevant information from that dataset and analyze it so that it would become enough to accomplish the goals. The goals of this phase is to make high quality dataset and to make a strong bond of this dataset with the target variable. This goal is achieved in following steps.
This is the initial phase of collecting data in which you collect the data from all available resources like websites and forums. Afterwards, you combine this dataset to analyze it and make a report out of it.
After collecting all the necessary data from available resources, the next step is to describe the data. Data description means that you will examine the data and create a data description report. The report must have all the properties of data such as data format, data size, number of records, and all the fields associated with the data. At the end of this phase your data description report will be ready and you are good to proceed to the next step.
The next step is to fully explore your data. Before moving towards the quality assessment, you need to have the good understanding of your data. Usually, the datasets are ambiguous, noisy, and have missing entities and values. Engineers use different data visualization and summarization tools to remove the ambiguous data and fill out the missing information about the data. In this step, data scientist query the data and check whether we are getting the required information or not. They visualize the data and make suitable relationships among them. One they are sure about the data, they make the data exploratory report.
After the successful data exploration and removing ambiguous data, the next step is to verify the quality of the dataset available. Data may not be 100% accurate but the quality can be maximizes by taking certain measures and steps.
In this way you can achieve the quality data. Now, this data will benefit engineers to stream line their tasks and it will be easy for them to operate on the data. Once your data is cleaned, make a data quality report.
In this phase you develop the final dataset for modeling. According to data mining experts and data scientists, preparing the data to further modeling is the main task in the whole project life cycle and it is a lengthy task. This step is also divided in to further steps.
In this step, the data is finalized and data engineers select the data to use. They also create the document stating the reason that why this particular dataset is selected and why the other is rejected.
After selection of the data, it is cleaned and data engineers remove all the duplicate values.
Data construction is also an interesting task in data preparation phase. In this phase you combine different attributes of the data to make a new attribute which will definitely help you. In general, when you combine orange and yellow color, it gives you a red. In the same way when you combine a data attribute height and weight, it will give you the body mass index.
Data integration is the technique in which data is combined from different heterogeneous data resources like databases and websites into a single file. It is the preprocessing technique and it gives a unified view of the data. There are two types of data integration:
We will discuss each in brief detail.
In this type of data integration, the data ware house is considered as the authentic resource of the data. Engineers gather the information from the data ware house. They gather the data from different resources and combine them into a single physical location for modeling. It involves the extraction, transformation and loading process.
In this type of data integration, an interface is developed through which the query is transferred to the database and it fetch the results according to the query of the user. The data is not duplicated and it remains only in the database.
There are several issues in data integration like schema integration, redundancy, detection and resolving data value conflicts.
Data wrangling is the way toward cleaning, organizing and enhancing crude data into an ideal configuration for better dynamic results in less time. It is also known as Data Munging some times. Data wrangling is progressively universal at the present top firms. Data has gotten more differing and unstructured, requesting expanded time spent separating, cleaning, and arranging data in front of more extensive examination. Simultaneously, with data illuminating pretty much every business choice, business clients have less an ideal opportunity to look out for specialized assets for arranged data.
Feature extraction is the process of extracting the relevant feature from the dataset. Data engineers select the feature from the dataset and extract it for their use. We have discussed about feature selection below. There are several features of the data which is in the dataset, but extracting the relevant feature is the goal of this step.
Attribute generation is also known as feature generation. In feature or attribute generation you pick one or two attributes from the available data in the dataset and combine them. It will generate a new feature for you. For example, you can take an average of two variables, and you can calculate the percentage of a value etc.
In attribute selection or feature selection, important and useful features are selected from the several available features in the dataset. It is considered the important process in data mining project life cycle as it allows you to judge which features are important for predicting models and how these attributes are related to each other. Data engineers select the good features and ignore the ambiguous data even after the cleaning process.
The last step before moving towards the modeling of the data is data formatting. In data formatting, engineers re-format the data for better understanding. It means to bring data to a common standard so that everyone can understand. Engineers can easily perform operations on the formatted dataset. For example, making all the characters as string data type.
According to data scientist experts, modeling is the least time consuming task in the project life cycle. Modeling is the very crucial step in CRISP – DM. In this step all the findings and cleaned data is executed for further evaluation. You have to provide the input to the model using different data modeling techniques. At this step, you are well aware of that which data model you have to choose. There are four more steps in this phase.
This is the first step in modeling and you have to choose the best possible modeling technique that you will use for training your model. On the other hand, you may have already selected the modeling methodology in early phase of CRIPS – DM that is business understanding. But now you will select the final modeling technique. Different modeling techniques are as follows:
If your experts think that many modeling techniques are applied then you should apply separately all the techniques and then fetch the results.
Before building the model, you have to generate the test designs to check for the validity and quality of the model. In this step, engineers tend to split their data into test, training and validating parts. For example in supervised data mining projects the error rates are considered to be the quality measure for data mining projects. The main goal of this phase is to divide your whole dataset into test dataset, validation dataset and training dataset.
In this step, engineers execute the modeling tool on the available fine dataset to generate one or more models. Before starting building the model you have to ensure few important things such as parameters. All modeling tools have their specific set of parameters that needs to be adjusted on the basis of target dataset. Set the parameters properly by mentioning their values. Now, your models have been built by using any modeling technique.
It is very important to measure the accuracy and efficiency of your data mining model. Although it is a tough task but you have to do it for accurate results. These data mining models are used for prediction and it is important to build a reliable model. This reliability often depends upon the selection of modeling technique. Every modeling technique has different criteria of model evaluation but the most common used are clustering, classification and regression. They are used in supervised data mining projects.
As discussed earlier there are several data mining models that fit into their own domain and specifications. Data scientists decipher the models as per their area information, their data mining achievement rules and the ideal test plan. Judge the accomplishment of the utilization of modeling and revelation strategies actually, at that point contact business investigators and domain specialists later so as to talk about the data mining brings about the business setting. This document just thinks about models, while the evaluation stage additionally considers all different outcomes that were delivered over the span of the task. At this point you should rank the models and survey them as indicated by the evaluation measures. You should consider the business targets and business achievement measures as far as possible here. In most data mining ventures a solitary procedure is applied more than once and data mining results are created with a few distinct methods. After this step, you have to fine tune the model until it becomes excellent to proceed further.
At this stage, our work is leading towards the finish line. Data engineers evaluate the obtained results. They check that whether the business objective is achieve or not. The results are evaluated on the basis of the requirements mentioned by the customer. This phase also has three steps.
Once the models are build and tuned, check that do they meet the client’s requirement or not. If they are not meeting the client’s business requirements build another one. Also check for the “SMART” objective.
Skim the whole process and check for the missing work. Check if all the steps were covered properly and do the correction of minor mistakes if any. Go through the documentation and finalize the process.
It is the step where you make the decision of deployment or making revisions or changes to the previous work. If you are not satisfied with the results or your customer is not satisfied, you can rebuild your data model. You can also build new data mining projects without deploying the existing one.
Once you have made the decision of bringing your model to life than its time to deploy your project. You have to deploy it so that customer or client can access it and he can enjoy the benefits of model. This last phase has also 4 steps.
Everything needs a proper documentation for keeping the record. In the same way, you have to develop a plan document to deploy the model.
As the name suggest, monitoring and maintenance plan is made to avoid any mishap in the future. Unfortunately, if the model get collapsed some engineer could make it. Moreover, if the model stops delivering the results, another data engineer could read the maintenance document and make it run.
Like every project, it is considered a good practice to create a final report of the completed project. This report might have a presentation of how all the tasks get completed and finalized. How the model was build and what measures were taken to build the data mining model. Moreover, it may also contain the results of the evaluation to be presented to the client upon final delivery.
This step is related to going through the documentation of whole project. Stakeholders check that how the project went through? What milestones have achieved and what hurdles came in the path? How can we improve our results? Which process methodology is better and why? All these things are noticed because they are very helpful in the future data mining projects.
This article covers all the important fields of data science including study of different data mining project life cycles. Moreover, different terminologies and concepts related to data mining and data science have been discussed. Moreover, in our opinion if you only focus on simple data and modeling, you will not be able to move ahead. That is why you need to focus on CRISP – DM methodology because it is the leading data mining project life cycle methodology. As you have seen before that it differs from the above two (KDD and SEMMA) in the way that it gives deployment advantage and business understanding. It is the most crucial part as all the other steps depend on this first step. We will also suggest you to read more about Machine Learning and Artificial Intelligence as they both are the innovation of this and next generation.
Address:
360DigiTMG - Data Analytics, Data Science Course Training Hyderabad
2-56/2/19, 3rd floor,, Vijaya towers, near Meridian school,, Ayyappa Society Rd, Madhapur,, Hyderabad, Telangana 500081
Phone: 099899 94319
Agra, Ahmedabad, Amritsar, Anand, Anantapur, Bangalore, Bhopal, Bhubaneswar, Chengalpattu, Chennai, Cochin, Dehradun, Malaysia, Dombivli, Durgapur, Ernakulam, Erode, Gandhinagar, Ghaziabad, Gorakhpur, Gwalior, Hebbal, Hyderabad, Jabalpur, Jalandhar, Jammu, Jamshedpur, Jodhpur, Khammam, Kolhapur, Kothrud, Ludhiana, Madurai, Meerut, Mohali, Moradabad, Noida, Pimpri, Pondicherry, Pune, Rajkot, Ranchi, Rohtak, Roorkee, Rourkela, Shimla, Shimoga, Siliguri, Srinagar, Thane, Thiruvananthapuram, Tiruchchirappalli, Trichur, Udaipur, Yelahanka, Andhra Pradesh, Anna Nagar, Bhilai, Borivali, Calicut, Chandigarh, Chromepet, Coimbatore, Dilsukhnagar, ECIL, Faridabad, Greater Warangal, Guduvanchery, Guntur, Gurgaon, Guwahati, Hoodi, Indore, Jaipur, Kalaburagi, Kanpur, Kharadi, Kochi, Kolkata, Kompally, Lucknow, Mangalore, Mumbai, Mysore, Nagpur, Nashik, Navi Mumbai, Patna, Porur, Raipur, Salem, Surat, Thoraipakkam, Trichy, Uppal, Vadodara, Varanasi, Vijayawada, Visakhapatnam, Tirunelveli, Aurangabad
ECIL, Jaipur, Pune, Gurgaon, Salem, Surat, Agra, Ahmedabad, Amritsar, Anand, Anantapur, Andhra Pradesh, Anna Nagar, Aurangabad, Bhilai, Bhopal, Bhubaneswar, Borivali, Calicut, Cochin, Chengalpattu , Dehradun, Dombivli, Durgapur, Ernakulam, Erode, Gandhinagar, Ghaziabad, Gorakhpur, Guduvanchery, Gwalior, Hebbal, Hoodi , Indore, Jabalpur, Jaipur, Jalandhar, Jammu, Jamshedpur, Jodhpur, Kanpur, Khammam, Kochi, Kolhapur, Kolkata, Kothrud, Ludhiana, Madurai, Mangalore, Meerut, Mohali, Moradabad, Pimpri, Pondicherry, Porur, Rajkot, Ranchi, Rohtak, Roorkee, Rourkela, Shimla, Shimoga, Siliguri, Srinagar, Thoraipakkam , Tiruchirappalli, Tirunelveli, Trichur, Trichy, Udaipur, Vijayawada, Vizag, Warangal, Chennai, Coimbatore, Delhi, Dilsukhnagar, Hyderabad, Kalyan, Nagpur, Noida, Thane, Thiruvananthapuram, Uppal, Kompally, Bangalore, Chandigarh, Chromepet, Faridabad, Guntur, Guwahati, Kharadi, Lucknow, Mumbai, Mysore, Nashik, Navi Mumbai, Patna, Pune, Raipur, Vadodara, Varanasi, Yelahanka


 091085 92130
091085 92130 


